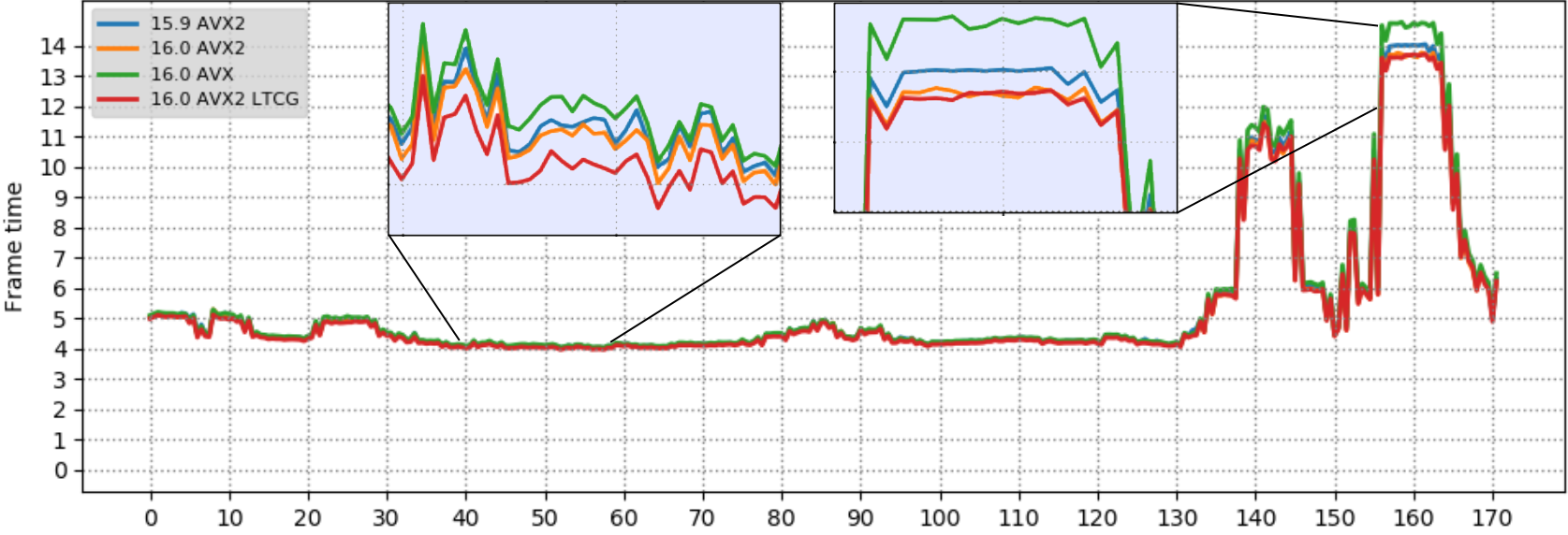
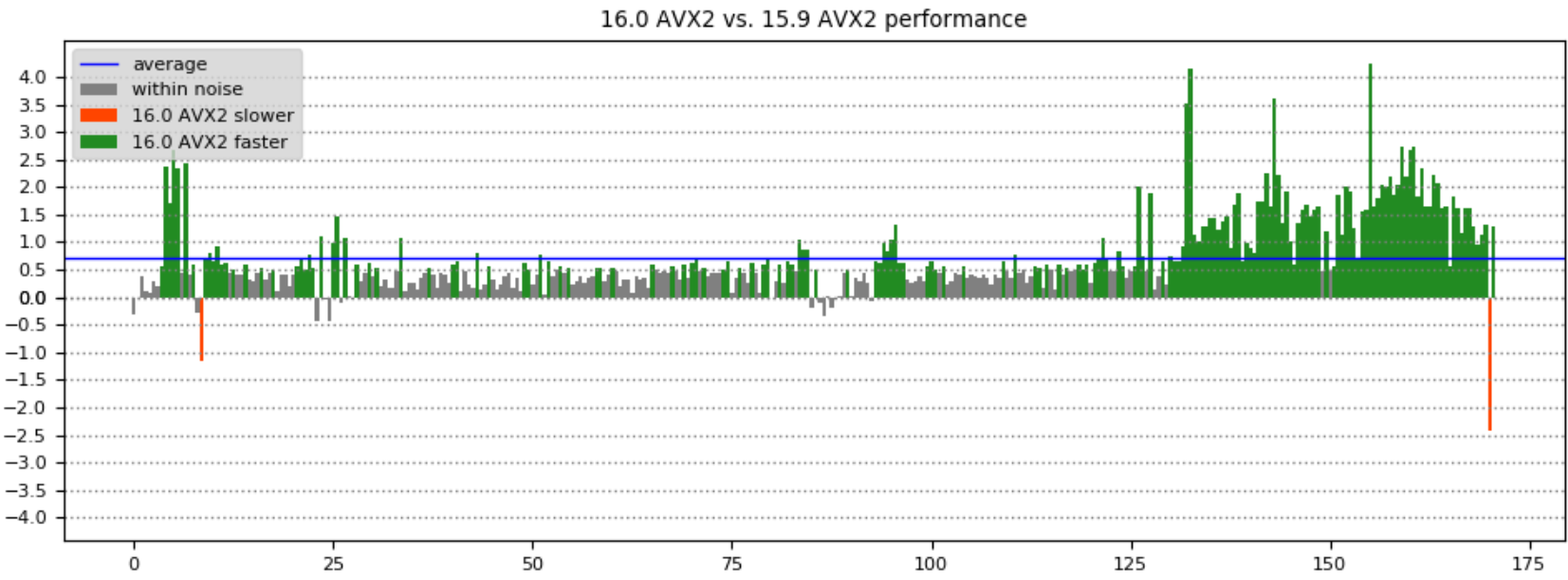
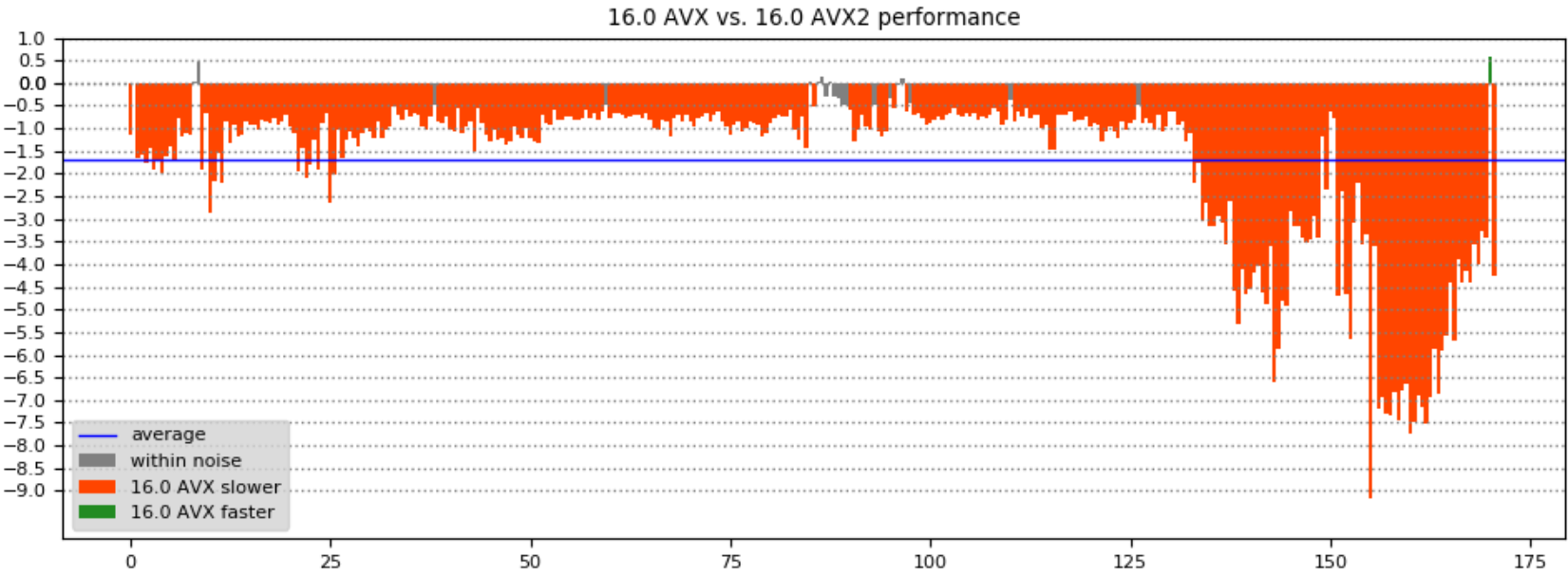
In the era of ubiquitous AI applications there is an emerging demand of the compiler accelerating computation-intensive machine-learning code for existing hardware. Such code usually does mathematical computation like matrix transformation and manipulation and it is usually in the form of loops. The SIMD extension of OpenMP provides users an effortless way to speed up loops by explicitly leveraging the vector unit of modern processors. We are proud to start offering C/C++ OpenMP SIMD vectorization in Visual Studio 2019.
The OpenMP C/C++ application program interface was originally designed to improve application performance by enabling code to be effectively executed in parallel on multiple processors in the 1990s. Over the years the OpenMP standard has been expanded to support additional concepts such as task-based parallelization, SIMD vectorization, and processor offloading. Since 2005, Visual Studio has supported the OpenMP 2.0 standard which focuses on multithreaded parallelization. As the world is moving into an AI era, we see a growing opportunity to improve code quality by expanding support of the OpenMP standard in Visual Studio. We continue our journey in Visual Studio 2019 by adding support for OpenMP SIMD.
OpenMP SIMD, first introduced in the OpenMP 4.0 standard, mainly targets loop vectorization. It is so far the most widely used OpenMP feature in machine learning according to our research. By annotating a loop with an OpenMP SIMD directive, the compiler can ignore vector dependencies and vectorize the loop as much as possible. The compiler respects users’ intention to have multiple loop iterations executed simultaneously.
#pragma omp simd
for (i = 0; i < count; i++)
{
a[i] = b[i] + 1;
}As you may know, C++ in Visual Studio already provides similar non-OpenMP loop pragmas like #pragma vector and #pragma ivdep. However, the compiler can do more with OpenMP SIMD. For example:
- The compiler is always allowed to ignore any vector dependencies that are present.
- /fp:fast is enabled within the loop.
- Loops with function calls are vectorizable.
- Outer loops are vectorizable.
- Nested loops can be coalesced into one loop and vectorized.
- Hybrid acceleration is achievable with #pragma omp for simd to enable coarse-grained multithreading and fine-grained vectorization.
In addition, the OpenMP SIMD directive can take the following clauses to further enhance the vectorization:
- simdlen(length) : specify the number of vector lanes
- safelen(length) : specify the vector dependency distance
- linear(list[ : linear-step]) : the linear mapping from loop induction variable to array subscription
- aligned(list[ : alignment]): the alignment of data
- private(list) : specify data privatization
- lastprivate(list) : specify data privatization with final value from the last iteration
- reduction(reduction-identifier : list) : specify customized reduction operations
- collapse(n) : coalescing loop nest
New -openmp:experimental switch
An OpenMP-SIMD-annotated program can be compiled with a new CL switch -openmp:experimental. This new switch enables additional OpenMP features not available under -openmp. While the name of this switch is “experimental”, the switch itself, and the functionality it enables is fully supported and production-ready. The name reflects that it doesn’t enable any complete subset or version of an OpenMP standard. Future iterations of the compiler may use this switch to enable additional OpenMP features and new OpenMP-related switches may be added. The -openmp:experimental switch subsumes the -openmp switch which means it is compatible with all OpenMP 2.0 features. Note that the SIMD directive and its clauses cannot be compiled with the -openmp switch.
For loops that are not vectorized, the compiler will issue a message for each of them like below. For example,
cl -O2 -openmp:experimental mycode.cpp
mycode.cpp(84) : info C5002: Omp simd loop not vectorized due to reason ‘1200’
mycode.cpp(90) : info C5002: Omp simd loop not vectorized due to reason ‘1200’
For loops that are vectorized, the compiler keeps silent unless a vectorization logging switch is provided:
cl -O2 -openmp:experimental -Qvec-report:2 mycode.cpp
mycode.cpp(84) : info C5002: Omp simd loop not vectorized due to reason ‘1200’
mycode.cpp(90) : info C5002: Omp simd loop not vectorized due to reason ‘1200’
mycode.cpp(96) : info C5001: Omp simd loop vectorized
As the first step of supporting OpenMP SIMD we have basically hooked up the SIMD pragma with the backend vectorizer under the new switch. We focused on vectorizing innermost loops by improving the vectorizer and alias analysis. None of the SIMD clauses are effective in Visual Studio 2019 at the time of this writing. They will be parsed but ignored by the compiler with a warning issued for user’s awareness. For example, the compiler will issue
warning C4849: OpenMP ‘simdlen’ clause ignored in ‘simd’ directive
for the following code:
#pragma omp simd simdlen(8)
for (i = 1; i < count; i++)
{
a[i] = a[i-1] + 1;
b[i] = *c + 1;
bar(i);
}
More about the semantics of OpenMP SIMD directive
The OpenMP SIMD directive provides users a way to dictate the compiler to vectorize a loop. The compiler is allowed to ignore the apparent legality of such vectorization by accepting users’ promise of correctness. It is users’ responsibility when unexpected behavior happens with the vectorization. By annotating a loop with the OpenMP SIMD directive, users intend to have multiple loop iterations executed simultaneously. This gives the compiler a lot of freedom to generate machine code that takes advantage of SIMD or vector resources on the target processor. While the compiler is not responsible for exploring the correctness and profit of such user-specified parallelism, it must still ensure the sequential behavior of a single loop iteration.
For example, the following loop is annotated with the OpenMP SIMD directive. There is no perfect parallelism among loop iterations since there is a backward dependency from a[i] to a[i-1]. But because of the SIMD directive the compiler is still allowed to pack consecutive iterations of the first statement into one vector instruction and run them in parallel.
#pragma omp simd
for (i = 1; i < count; i++)
{
a[i] = a[i-1] + 1;
b[i] = *c + 1;
bar(i);
}Therefore, the following transformed vector form of the loop is legal because the compiler keeps the sequential behavior of each original loop iteration. In other words, a[i] is executed after a[-1], b[i] is after a[i] and the call to bar happens at last.
#pragma omp simd
for (i = 1; i < count; i+=4)
{
a[i:i+3] = a[i-1:i+2] + 1;
b[i:i+3] = *c + 1;
bar(i);
bar(i+1);
bar(i+2);
bar(i+3);
}It is illegal to move the memory reference *c out of the loop if it may alias with a[i] or b[i]. It’s also illegal to reorder the statements inside one original iteration if it breaks the sequential dependency. As an example, the following transformed loop is not legal.
c = b;
t = *c;
#pragma omp simd
for (i = 1; i < count; i+=4)
{
a[i:i+3] = a[i-1:i+2] + 1;
bar(i); // illegal to reorder if bar[i] depends on b[i]
b[i:i+3] = t + 1; // illegal to move *c out of the loop
bar(i+1);
bar(i+2);
bar(i+3);
}
Future Plans and Feedback
We encourage you to try out this new feature. As always, we welcome your feedback. If you see an OpenMP SIMD loop that you expect to be vectorized, but isn’t or the generated code is not optimal, please let us know. We can be reached via the comments below, via email (visualcpp@microsoft.com), twitter (@visualc) , or via Developer Community.
Moving forward, we’d love to hear your need of OpenMP functionalities missing in Visual Studio. As there have been several major evolutions in OpenMP since the 2.0 standard, OpenMP now has tremendous features to ease your effort to build high-performance programs. For instance, task-based concurrency programming is available starting from OpenMP 3.0. Heterogenous computing (CPU + accelerators) is supported in OpenMP 4.0. Advanced SIMD vectorization and DOACROSS loop parallelization support are also available in the latest OpenMP standard now. Please check out the complete standard revisions and feature sets from the OpenMP official website: https://www.openmp.org. We sincerely ask for your thoughts on the specific OpenMP features you would like to see. We’re also interested in hearing about how you’re using OpenMP to accelerate your code. Your feedback is critical that it will help drive the direction of OpenMP support in Visual Studio.
The post SIMD Extension to C++ OpenMP in Visual Studio appeared first on C++ Team Blog.