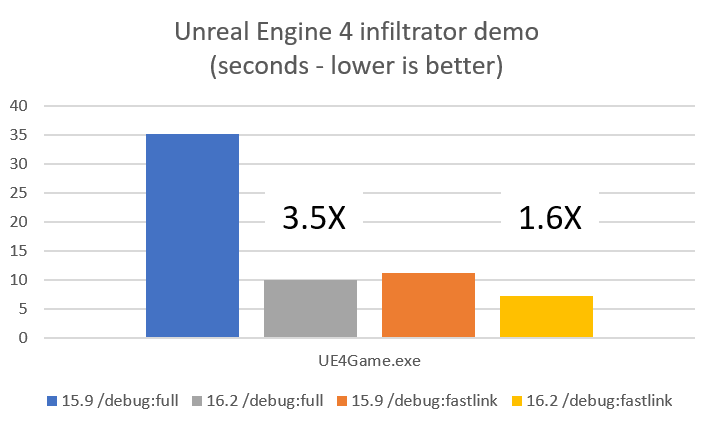
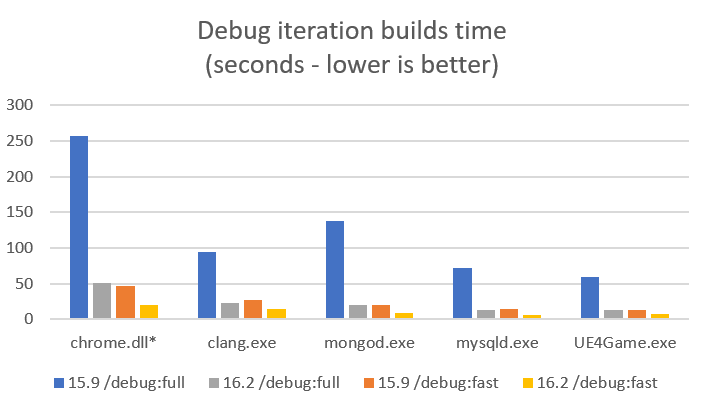
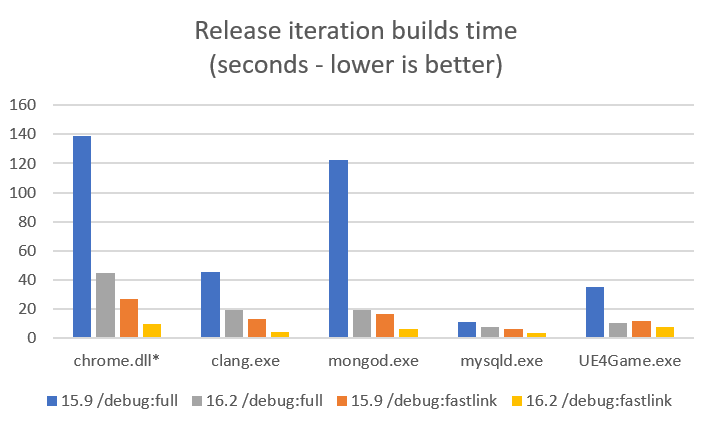
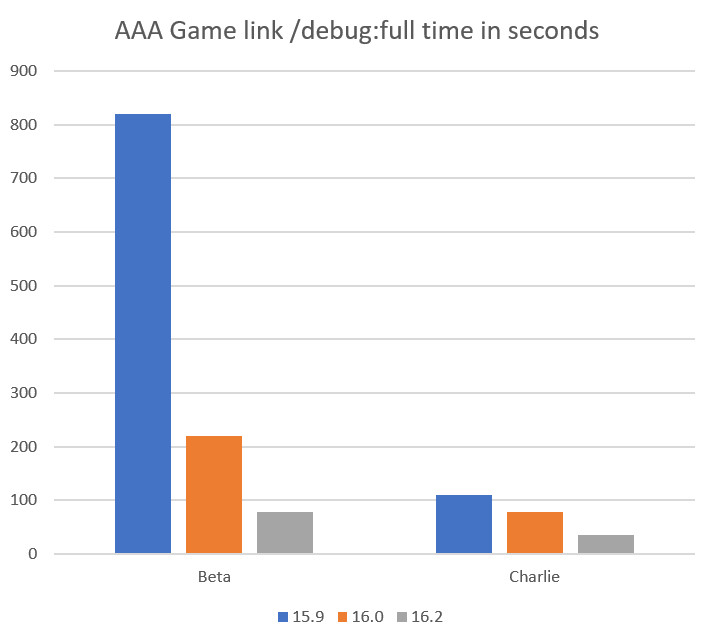
This post is part of a regular series of posts where the C++ product team here at Microsoft and other guests answer questions we have received from customers. The questions can be about anything C++ related: MSVC toolset, the standard language and library, the C++ standards committee, isocpp.org, CppCon, etc. Today’s post is by Cameron DaCamara.
C++20 adds a new operator, affectionately dubbed the “spaceship” operator: <=>. There was a post awhile back by our very own Simon Brand detailing some information regarding this new operator along with some conceptual information about what it is and does. The goal of this post is to explore some concrete applications of this strange new operator and its associated counterpart, the operator== (yes it has been changed, for the better!), all while providing some guidelines for its use in everyday code.
Comparisons
It is not an uncommon thing to see code like the following:
struct IntWrapper {
int value;
constexpr IntWrapper(int value): value{value} { }
bool operator==(const IntWrapper& rhs) const { return value == rhs.value; }
bool operator!=(const IntWrapper& rhs) const { return !(*this == rhs); }
bool operator<(const IntWrapper& rhs) const { return value < rhs.value; }
bool operator<=(const IntWrapper& rhs) const { return !(rhs < *this); }
bool operator>(const IntWrapper& rhs) const { return rhs < *this; }
bool operator>=(const IntWrapper& rhs) const { return !(*this < rhs); }
};Note: eagle-eyed readers will notice this is actually even less verbose than it should be in pre-C++20 code because these functions should actually all be nonmember friends, more about that later.
That is a lot of boilerplate code to write just to make sure that my type is comparable to something of the same type. Well, OK, we deal with it for awhile. Then comes someone who writes this:
constexpr bool is_lt(const IntWrapper& a, const IntWrapper& b) {
return a < b;
}
int main() {
static_assert(is_lt(0, 1));
}The first thing you will notice is that this program will not compile.
error C3615: constexpr function 'is_lt' cannot result in a constant expression
Ah! The problem is that we forgot constexpr on our comparison function, drat! So one goes and adds constexpr to all of the comparison operators. A few days later someone goes and adds a is_gt helper but notices all of the comparison operators do not have an exception specification and goes through the same tedious process of adding noexcept to each of the 5 overloads.
This is where C++20’s new spaceship operator steps in to help us out. Let’s see how the original IntWrapper can be written in a C++20 world:
#include <compare>
struct IntWrapper {
int value;
constexpr IntWrapper(int value): value{value} { }
auto operator<=>(const IntWrapper&) const = default;
};The first difference you may notice is the new inclusion of <compare>. The <compare> header is responsible for populating the compiler with all of the comparison category types necessary for the spaceship operator to return a type appropriate for our defaulted function. In the snippet above, the return type auto will be deduced to std::strong_ordering.
Not only did we remove 5 superfluous lines, but we don’t even have to define anything, the compiler does it for us! Our is_lt remains unchanged and just works while still being constexpr even though we didn’t explicitly specify that in our defaulted operator<=>. That’s well and good but some people may be scratching their heads as to why is_lt is allowed to still compile even though it does not even use the spaceship operator at all. Let’s explore the answer to this question.
Rewriting Expressions
In C++20, the compiler is introduced to a new concept referred to “rewritten” expressions. The spaceship operator, along with operator==, are among the first two candidates subject to rewritten expressions. For a more concrete example of expression rewriting, let us break down the example provided in is_lt.
During overload resolution the compiler is going to select from a set of viable candidates, all of which match the operator we are looking for. The candidate gathering process is changed very slightly for the case of relational and equivalency operations where the compiler must also gather special rewritten and synthesized candidates ([over.match.oper]/3.4).
For our expression a < b the standard states that we can search the type of a for an operator<=> or a namespace scope function operator<=> which accepts its type. So the compiler does and it finds that, in fact, a‘s type does contain IntWrapper::operator<=>. The compiler is then allowed to use that operator and rewrite the expression a < b as (a <=> b) < 0. That rewritten expression is then used as a candidate for normal overload resolution.
You may find yourself asking why this rewritten expression is valid and correct. The correctness of the expression actually stems from the semantics the spaceship operator provides. The <=> is a three-way comparison which implies that you get not just a binary result, but an ordering (in most cases) and if you have an ordering you can express that ordering in terms of any relational operations. A quick example, the expression 4 <=> 5 in C++20 will give you back the result std::strong_ordering::less. The std::strong_ordering::less result implies that 4 is not only different from 5 but it is strictly less than that value, this makes applying the operation (4 <=> 5) < 0 correct and exactly accurate to describe our result.
Using the information above the compiler can take any generalized relational operator (i.e. <, >, etc.) and rewrite it in terms of the spaceship operator. In the standard the rewritten expression is often referred to as (a <=> b) @ 0 where the @ represents any relational operation.
Synthesizing Expressions
Readers may have noticed the subtle mention of “synthesized” expressions above and they play a part in this operator rewriting process as well. Consider a different predicate function:
constexpr bool is_gt_42(const IntWrapper& a) {
return 42 < a;
}If we use our original definition for IntWrapper this code will not compile.
error C2677: binary '<': no global operator found which takes type 'const IntWrapper' (or there is no acceptable conversion)
This makes sense in pre-C++20 land, and the way to solve this problem would be to add some extra friend functions to IntWrapper which take a left-hand side of int. If you try to build that sample with a C++20 compiler and our C++20 definition of IntWrapper you might notice that it, again, “just works”—another head scratcher. Let’s examine why the code above is still allowed to compile in C++20.
During overload resolution the compiler will also gather what the standard refers to as “synthesized” candidates, or a rewritten expression with the order of the parameters reversed. In the example above the compiler will try to use the rewritten expression (42 <=> a) < 0 but it will find that there is no conversion from IntWrapper to int to satisfy the left-hand side so that rewritten expression is dropped. The compiler also conjures up the “synthesized” expression 0 < (a <=> 42) and finds that there is a conversion from int to IntWrapper through its converting constructor so this candidate is used.
The goal of the synthesized expressions are to avoid the mess of needing to write the boilerplate of friend functions to fill in gaps where your object could be converted from other types. Synthesized expressions are generalized to 0 @ (b <=> a).
More Complex Types
The compiler-generated spaceship operator doesn’t stop at single members of classes, it will generate a correct set of comparisons for all of the sub-objects within your types:
struct Basics {
int i;
char c;
float f;
double d;
auto operator<=>(const Basics&) const = default;
};
struct Arrays {
int ai[1];
char ac[2];
float af[3];
double ad[2][2];
auto operator<=>(const Arrays&) const = default;
};
struct Bases : Basics, Arrays {
auto operator<=>(const Bases&) const = default;
};
int main() {
constexpr Bases a = { { 0, 'c', 1.f, 1. },
{ { 1 }, { 'a', 'b' }, { 1.f, 2.f, 3.f }, { { 1., 2. }, { 3., 4. } } } };
constexpr Bases b = { { 0, 'c', 1.f, 1. },
{ { 1 }, { 'a', 'b' }, { 1.f, 2.f, 3.f }, { { 1., 2. }, { 3., 4. } } } };
static_assert(a == b);
static_assert(!(a != b));
static_assert(!(a < b));
static_assert(a <= b);
static_assert(!(a > b));
static_assert(a >= b);
}The compiler knows how to expand members of classes that are arrays into their lists of sub-objects and compare them recursively. Of course, if you wanted to write the bodies of these functions yourself you still get the benefit of the compiler rewriting expressions for you.
Looks Like a Duck, Swims Like a Duck, and Quacks Like operator==
Some very smart people on the standardization committee noticed that the spaceship operator will always perform a lexicographic comparison of elements no matter what. Unconditionally performing lexicographic comparisons can lead to inefficient generated code with the equality operator in particular.
The canonical example is comparing two strings. If you have the string "foobar" and you compare it to the string "foo" using == one would expect that operation to be nearly constant. The efficient string comparison algorithm is thus:
- First compare the size of the two strings, if the sizes differ return
false, otherwise
- step through each element of the two strings in unison and compare until one differs or the end is reached, return the result.
Under spaceship operator rules we need to start with the deep comparison on each element first until we find the one that is different. In the our example of "foobar" and "foo" only when comparing 'b' to '\0' do you finally return false.
To combat this there was a paper, P1185R2 which details a way for the compiler to rewrite and generate operator== independently of the spaceship operator. Our IntWrapper could be written as follows:
#include <compare>
struct IntWrapper {
int value;
constexpr IntWrapper(int value): value{value} { }
auto operator<=>(const IntWrapper&) const = default;
bool operator==(const IntWrapper&) const = default;
};Just one more step… however, there’s good news; you don’t actually need to write the code above, because simply writing auto operator<=>(const IntWrapper&) const = default is enough for the compiler to implicitly generate the separate—and more efficient—operator== for you!
The compiler applies a slightly altered “rewrite” rule specific to == and != wherein these operators are rewritten in terms of operator== and not operator<=>. This means that != also benefits from the optimization, too.
Old Code Won’t Break
At this point you might be thinking, OK if the compiler is allowed to perform this operator rewriting business what happens when I try to outsmart the compiler:
struct IntWrapper {
int value;
constexpr IntWrapper(int value): value{value} { }
auto operator<=>(const IntWrapper&) const = default;
bool operator<(const IntWrapper& rhs) const { return value < rhs.value; }
};
constexpr bool is_lt(const IntWrapper& a, const IntWrapper& b) {
return a < b;
}The answer here is, you didn’t. The overload resolution model in C++ has this arena where all of the candidates do battle, and in this specific battle we have 3 candidates:
-
IntWrapper::operator<(const IntWrapper& a, const IntWrapper& b)IntWrapper::operator<=>(const IntWrapper& a, const IntWrapper& b)
(rewritten)
-
IntWrapper::operator<=>(const IntWrapper& b, const IntWrapper& a)
(synthesized)
If we accepted the overload resolution rules in C++17 the result of that call would have been ambiguous, but the C++20 overload resolution rules were changed to allow the compiler to resolve this situation to the most logical overload.
There is a phase of overload resolution where the compiler must perform a series tiebreakers. In C++20, there is a new tiebreaker that states we must prefer overloads that are not rewritten or synthesized, this makes our overload IntWrapper::operator< the best candidate and resolves the ambiguity. This same machinery prevents synthesized candidates from stomping on regular rewritten expressions.
Closing Thoughts
The spaceship operator is a welcomed addition to C++ and it is one of the features that will simplify and help you to write less code, and, sometimes, less is more. So buckle up with C++20’s spaceship operator!
We urge you to go out and try the spaceship operator, it’s available right now in Visual Studio 2019 under /std:c++latest! As a note, the changes introduced through P1185R2 will be available in Visual Studio 2019 version 16.2. Please keep in mind that the spaceship operator is part of C++20 and is subject to some changes up until such a time that C++20 is finalized.
As always, we welcome your feedback. Feel free to send any comments through e-mail at visualcpp@microsoft.com, through Twitter @visualc, or Facebook at Microsoft Visual Cpp. Also, feel free to follow me on Twitter @starfreakclone.
If you encounter other problems with MSVC in VS 2019 please let us know via the Report a Problem option, either from the installer or the Visual Studio IDE itself. For suggestions or bug reports, let us know through DevComm.
The post Simplify Your Code With Rocket Science: C++20’s Spaceship Operator appeared first on C++ Team Blog.